2022.03.26 - [프로그래밍/Python] - Selenium 기본기 및 참고 코드
Sample1.
Remember. Country 생성하는 방법 유용하다고 생각됨.
from selenium import webdriver
with webdirver.Firefox() as driver:
driver.get('https://www.scrapethissite.com/pages/simple/')
# 해당 페이지에서 국가, 수도, 인구, 면적을 모두 추출해 온다.
class Country:
def __init__(self, name, capital, population, area):
self.name = name
self.capital= capital
self.population = int(population)
country_list =[]
# 정보를 담을 빈공간 생성
div_list = driver.find_elements_by_class_name('country')
# 각 국가마다 country class에 정보가 담겨 있어 country class 요소들 모두 찾기
for div in div_list:
name= div.find_element_by_tag_name('h3').text
capital=div.find_element_by_class_name('country-capital').text
population=div.find_element_by_class_name('country-population').text
area=div.find_element_by_class_name('country-area').text
## 데이터들 찾아서 뽑아서
country= Country(name, capital, population, area)
country_list.append(country)
## 위에서 뽑아온 정보들을 이제 country_list 안에 담아주기
Sample2.
Remember. text 가 아닌 html 내 속성값을 가져오려 할 때는 .get_attribute("") 활용
from selenium import webdriver
with webdriver.Firefox() as driver:
driver.get('http://books.toscrape.com/catalogue/category/books/mystery_3/index.html')
# Q. 해당 페이지에서 제목만 모두 추출해오기
titles = []
tit_list=driver.find_elements_by_class_name('product_pod')
#책 제목이 product_pod class가 적용된 곳에 있음을 확인
for tit in tit_list:
titl = tit.find_element_by_tag_name('h3')\
.find_element_by_tag_name('a').get_attribute('title')
# 그 리스트들 중 h3 태그 안의 a 태그의 title="abcd" 에 있는 abcd 를 가져오기
# text가 아니라 특성을 가져오려면 .get_attribute('xxx') 활용
titl=str(titl)
titles.append(titl)
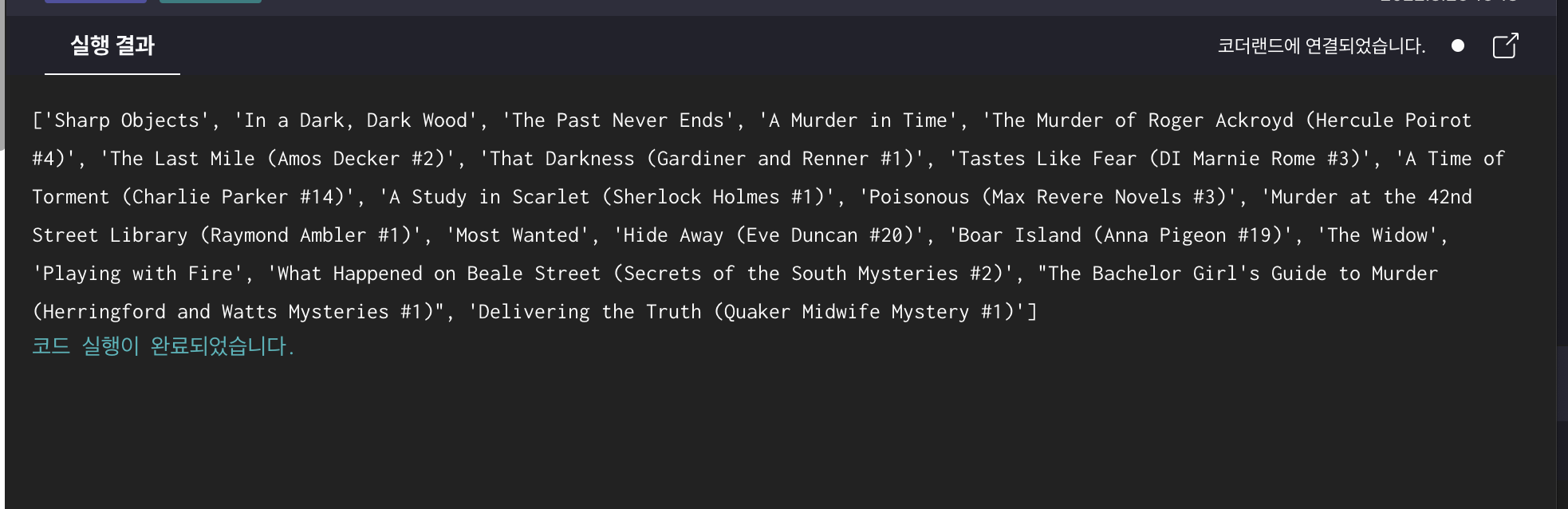
print(titles)
Sample1_2
# Q1-2 단위를 뺀 가격 정보만 가져올 것
prices = []
p_list=driver.find_elements_by_class_name('product_price')
for p in p_list:
pri = p.find_element_by_class_name('price_color').text
if '£' in pri:
a,b =pri.split('£')
# 가져온 정보에서 파운드기호를 기준으로 a,b로 분리하고
pri=float(b)
#b만 들고와서 float형으로 pri에 저장하자
prices.append(pri)
Sample3. high level
Remember. 전반적인 흐름구조를 짜야함.
- 검색어떻게 할지?
- 모든 페이지를 어떻게 가져올지?
- 필요 정보들을 하나씩 꺼내오기
Remember. 페이지를 넘어가는 걸 아래처럼 할 수도 있다는 거
Remember. key별 집계 방법 코드 방식 (for 구문 활용)
Remember. max 수치를 가져오는 또 다른 방법 (for 구문 활용)
from selenium import webdriver
from typing import NameTuple
class Record(NamedTuple):
name: str
year: int
wins: int
losses: int
# 값들을 넣을 dictionary 공간을 생성
with webdriver.Firefox() as driver:
driver.get('https://www.scrapethissite.com/pages/forms/')
##STEP 1.검색
input_e = driver.find_element_by_id('q')
# 웹 상에서 검색어를 입력하는 공간을 찾아
search_e = driver.find_element_by_xpath('//*[@id="hockey"]/div/div[4]/div/form/input[2]')
# 검색버튼을 찾아주기 (xpath 경로는 우클릭 복사로 찾아내3)
## Action 스타트~!
input_e.send_keys('New')
# New라는 검색어를 입력하고
search_e.click()
# search_e에 찾아놓은 버튼을 클릭해랏!
##STEP 2.페이지 넘기기
record_list = []
# 결과물을 담을 공간을 만들고
ul = driver.find_element_by_class_name('pagination')
a_list = ul.find_elements_by_tag_name('a')
url_list =[]
for a in a_list[:-1]:
# 마지막꺼는 불필요해서 제거하고 range
url_list.append(a.get_attribute('href'))
#추출 요소에서 href에 있는 링크만 모두 가져오기
##STEP 3.모든 N개 페이지의 정보 줍줍
for url in url_list:
driver.get(url)
#STEP2에서 찾아온 url을 넣어 반복 실행하는 구조
tbody = driver.find_element_by_tag_name('tbody')
team_list = tbody.find_elements_by_class_name('team')
for team in team_list:
name = team.find_element_by_class_name('name').text
year = team.find_element_by_class_name('year').text
wins = team.find_element_by_class_name('wins').text
losses = team.find_element_by_class_name('losses').text
record = Record(
name=name,
year=int(year),
wins=int(wins),
losses=int(losses)
)
record_list.append(record)
##Advanced 1 . 년도별 승수 합산.
win_dict = {}
# 정보를 담을 dictionary 공간 만들고
for record in record_list:
if record.year not in win_dict:
win_dict[record.year] = 0
# if문은 dictionary초기화와 같다고 생각해주면됨.
win_dict[record.year] +=record.wins
#record.year 에 승수를 더해나가는 걸 반복하면 사실상 년도별 승수합산 결과물 도출 가능!
##Advanced 2 . 가장 승수가 높은 해는?
best_year = 1990
# 우선 아무때로나 가정하는 겨
for year in win_dict:
if win_dict[year] > win_dict[best_year]:
# 최고의해보다 year의 승수가 높다면
best_year= year
# 최고의해를 방금 넣은 year로 바꾸기를 반복하면 결국 승수가 가장 높은 해가 추출!'프로그래밍 > Python' 카테고리의 다른 글
| Selenium. 특정 텍스트 포함 찾기 및 클릭 with xpath (0) | 2022.07.28 |
|---|---|
| Selenium 기본기 및 참고 코드 (0) | 2022.03.26 |
| Python : 여러개의 DataFrame을 각 시트별로 엑셀 파일에 저장 (2) | 2020.10.08 |
| Python으로 주식 데이터 불러오기 - pandas_datareader (0) | 2020.03.24 |


댓글